
BLOG
Request ID: The Complete Guide to Implementation, Debugging & Distributed Tracing
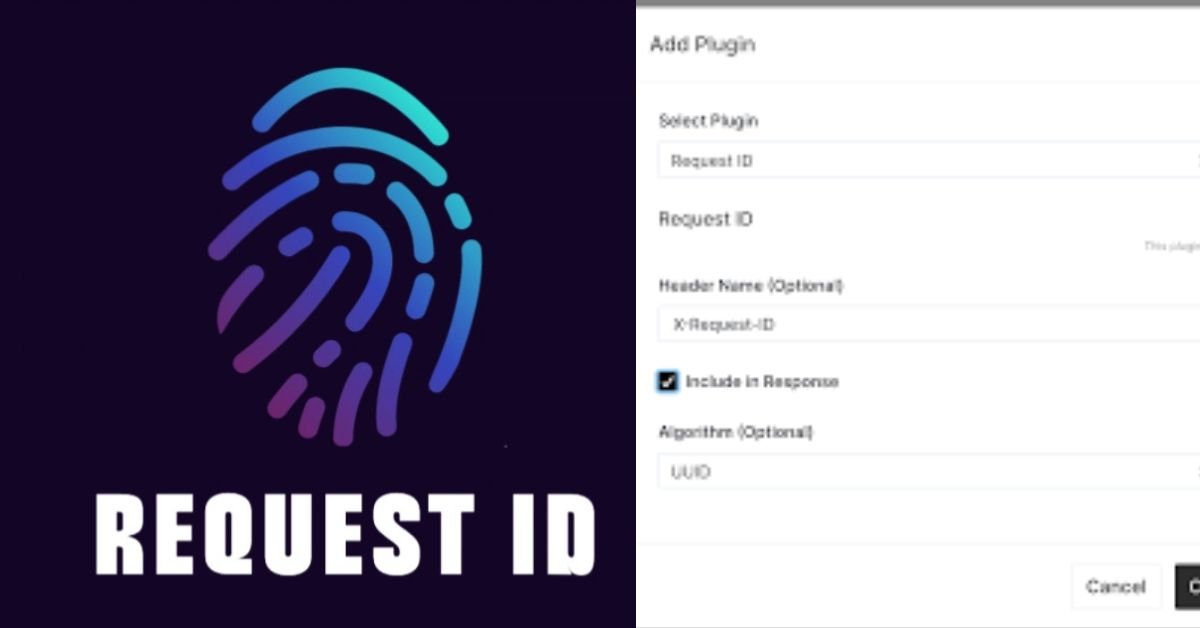
Request ID Debugging a production error without proper request tracking is like trying to find a specific conversation in a crowded room where everyone is talking at once. When multiple users experience issues simultaneously, isolating a single problematic transaction becomes nearly impossible. Request IDs solve this fundamental challenge by assigning a unique identifier to each HTTP request, creating a traceable thread through your entire application stack.
This comprehensive guide covers everything from basic implementation to advanced distributed tracing patterns, helping you reduce mean time to resolution (MTTR) by up to 70% while improving system observability and customer support efficiency.
What is a Request ID? Definition & Core Concepts
The Problem: Debugging Without Request Tracking
Consider this common scenario: Your monitoring system alerts you to a spike in 500 errors. You open the logs and see hundreds of error messages from the same timeframe. Which error belongs to which user? Which request triggered the cascade of failures? Without request tracking, engineers waste hours correlating timestamps, user agents, and IP addresses—often unsuccessfully.
The challenges multiply in modern architectures:
- Multiple concurrent requests from the same user
- Load-balanced servers processing overlapping transactions
- Microservices generating logs across distributed systems
- Asynchronous operations losing context across event boundaries
- Customer support teams unable to reference specific error instances
How Request IDs Solve Tracing Problems
A request ID is a unique identifier—typically a UUID (Universally Unique Identifier)—assigned to each incoming HTTP request. This identifier propagates through your entire request-response cycle, appearing in:
- Application logs at every processing stage
- HTTP response headers returned to clients
- Error messages and exception stack traces
- Monitoring system traces and metrics
- Database query logs and transaction records
- Message queue payloads and event streams
The request ID acts as a golden thread that ties together all activities related to a single user transaction. When an error occurs, engineers can search logs using the request ID to reconstruct the exact sequence of events, regardless of which servers or services were involved.
Request ID vs Correlation ID: Key Differences
While often used interchangeably, these terms have distinct meanings in distributed systems:
| Aspect | Request ID | Correlation ID |
| Scope | Single service/request | Multiple services/entire transaction |
| Lifespan | One HTTP request-response | Entire business transaction across services |
| Use Case | Debugging within one application | Tracing across microservices architecture |
Best Practice: In microservices environments, generate a correlation ID at the API gateway and a unique request ID for each internal service call. This creates both high-level transaction tracking and granular service-level debugging.
Key Benefits & Business Value of Request IDs
Accelerated Debugging & Reduced MTTR
Request IDs dramatically reduce the time engineers spend isolating and diagnosing issues. Industry data suggests teams implementing comprehensive request tracking see:
- 40-70% reduction in average debugging time
- 60% faster root cause analysis in distributed systems
- 80% improvement in first-time fix rate for production bugs
- Reduction in MTTR from hours to minutes for critical incidents
Instead of manually correlating timestamps and IP addresses across multiple log files, engineers simply grep for the request ID and immediately see the complete transaction timeline.
Enhanced User Experience & Support Efficiency
When users encounter errors, displaying the request ID creates a shared reference point between customers and support teams:
- Users can report “Error ID: abc-123” instead of vague descriptions
- Support agents instantly access relevant logs without interrogating users
- Reduced back-and-forth communication and faster resolution
- Professional appearance builds user confidence in your error handling
- Automated ticket systems can pre-populate context from request IDs
Example user-facing error:
“We are sorry, something went wrong. Please contact support with Error ID: 7f9a4e3c-2b1d-4a5e-8c3f-1e2d3c4b5a6f”
Distributed System Observability
In microservices architectures, a single user request might traverse a dozen services. Request IDs (combined with correlation IDs) enable:
- End-to-end transaction tracing across service boundaries
- Performance bottleneck identification at each service hop
- Dependency mapping and service interaction visualization
- Cascading failure analysis and circuit breaker optimization
- Integration with distributed tracing tools (Jaeger, Zipkin, OpenTelemetry)
Compliance & Audit Trail Creation
Request IDs create immutable audit trails for regulatory compliance:
- Financial services: PCI-DSS and SOC 2 audit requirements
- Healthcare: HIPAA-compliant activity logging
- E-commerce: Payment processing verification and dispute resolution
- Data privacy: GDPR/CCPA access request and deletion tracking
- Security incidents: Forensic investigation and breach analysis
Implementing Request IDs: Complete Technical Guide
HTTP Header Standards & Best Practices
While no official HTTP standard mandates specific headers, industry conventions have emerged:
| Header Name | Common Usage | Recommendation |
| X-Request-ID | Single service request tracking | Use for internal service requests |
| X-Correlation-ID | Multi-service transaction tracking | Use for end-to-end workflows |
| Request-ID | RFC-compliant alternative | Gaining adoption, more standard |
Convention: Always include the request ID in both the request headers (for propagation) and response headers (for client visibility). Many platforms like Heroku and AWS automatically add X-Request-ID headers.
Generating Effective Request IDs
UUID Version 4 (random) remains the most common choice for request IDs:
- Statistically unique without coordination: ~0% collision probability
- No sequential information leakage (unlike auto-incrementing IDs)
- Standard format: 550e8400-e29b-41d4-a716-446655440000
- Widely supported across all programming languages
- URL-safe and easily parseable
Alternative: UUID Version 7 (time-ordered) offers better database indexing performance for high-volume systems while maintaining uniqueness. Consider v7 if you store request IDs in indexed database columns.
Performance Note: UUID generation overhead is negligible (~1-2 microseconds). The performance impact of adding request IDs to headers and logs is unmeasurable in production systems.
Platform-Specific Implementation Guides
Node.js & Express Implementation
Express middleware provides the cleanest approach for request ID generation and propagation:
const express = require(‘express’);
const { v4: uuidv4 } = require(‘uuid’);
const app = express();
// Request ID middleware – place before all other middleware
app.use((req, res, next) => {
// Check for existing request ID (from upstream proxy/gateway)
const requestId = req.headers[‘x-request-id’] || uuidv4();
// Attach to request object for easy access
req.requestId = requestId;
// Add to response headers
res.setHeader(‘X-Request-ID’, requestId);
next();
});
// Custom logger that includes request ID
function log(req, level, message) {
console.log(JSON.stringify({
timestamp: new Date().toISOString(),
level: level,
requestId: req.requestId,
message: message
}));
}
// Example route using request ID
app.get(‘/api/users/:id’, async (req, res) => {
log(req, ‘info’, `Fetching user ${req.params.id}`);
try {
const user = await getUserById(req.params.id);
log(req, ‘info’, ‘User fetched successfully’);
res.json(user);
} catch (error) {
log(req, ‘error’, `Failed to fetch user: ${error.message}`);
res.status(500).json({
error: ‘Internal server error’,
requestId: req.requestId
});
}
});
app.listen(3000)
Python (Django/Flask) Implementation
Flask example with request context and structured logging:
from flask import Flask, request, g
import uuid
import logging
import json
app = Flask(__name__)
# Configure structured JSON logging
class RequestIdFilter(logging.Filter):
def filter(self, record):
record.request_id = getattr(g, ‘request_id’, ‘no-request-id’)
return True
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
logger.addFilter(RequestIdFilter())
@app.before_request
def add_request_id():
# Check for existing request ID or generate new one
g.request_id = request.headers.get(‘X-Request-ID’, str(uuid.uuid4()))
@app.after_request
def add_request_id_header(response):
response.headers[‘X-Request-ID’] = g.request_id
return response
@app.route(‘/api/users/<user_id>’)
def get_user(user_id):
logger.info(f’Fetching user {user_id}’, extra={
‘request_id’: g.request_id,
‘user_id’: user_id
})
try:
user = fetch_user_from_db(user_id)
return {‘user’: user}
except Exception as e:
logger.error(f’Error fetching user: {str(e)}’, extra={
‘request_id’: g.request_id,
‘user_id’: user_id
})
return {‘error’: ‘Internal server error’, ‘requestId’: g.request_id}, 500
if __name__ == ‘__main__’:
app.run()
Django Implementation: Create custom middleware in middleware.py and add request ID to the LogRecord using a filter, similar to the Flask example above.
Java Spring Boot Implementation
Spring Boot uses filters and MDC (Mapped Diagnostic Context) for thread-local request tracking:
import org.slf4j.MDC;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.UUID;
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class RequestIdFilter implements Filter {
private static final String REQUEST_ID_HEADER = “X-Request-ID”;
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) request;
HttpServletResponse httpResponse = (HttpServletResponse) response;
// Get or generate request ID
String requestId = httpRequest.getHeader(REQUEST_ID_HEADER);
if (requestId == null || requestId.isEmpty()) {
requestId = UUID.randomUUID().toString();
}
// Store in MDC for logging
MDC.put(“requestId”, requestId);
// Add to response headers
httpResponse.setHeader(REQUEST_ID_HEADER, requestId);
try {
chain.doFilter(request, response);
} finally {
// Always clear MDC to prevent thread-local leaks
MDC.clear();
}
}
}
// Configure logback.xml to include MDC values:
// <pattern>%d{ISO8601} [%thread] %-5level %logger{36} [%X{requestId}] – %msg%n</pattern>
.NET Core Implementation
.NET Core middleware with ILogger integration:
using Microsoft.AspNetCore.Http;
using System;
using System.Threading.Tasks;
public class RequestIdMiddleware
{
private readonly RequestDelegate _next;
private const string RequestIdHeader = “X-Request-ID”;
public RequestIdMiddleware(RequestDelegate next)
{
_next = next;
}
public async Task InvokeAsync(HttpContext context)
{
// Get or generate request ID
var requestId = context.Request.Headers[RequestIdHeader].FirstOrDefault()
?? Guid.NewGuid().ToString();
// Store in HttpContext.Items for access throughout request
context.Items[“RequestId”] = requestId;
// Add to response headers
context.Response.Headers[RequestIdHeader] = requestId;
// Add to logging scope
using (_logger.BeginScope(new Dictionary<string, object>
{
[“RequestId”] = requestId
}))
{
await _next(context);
}
}
}
// Register in Startup.cs:
// app.UseMiddleware<RequestIdMiddleware>();
// Access in controllers:
var requestId = HttpContext.Items[“RequestId”]?.ToString();
Passing Request IDs Across Service Boundaries
In distributed systems, request IDs must propagate through all service-to-service communications:
HTTP Client Configuration:
// Node.js example – propagate request ID to downstream services
const axios = require(‘axios’);
async function callDownstreamService(requestId, userId) {
const response = await axios.get(`https://user-service/api/users/${userId}`, {
headers: {
‘X-Request-ID’: requestId,
‘X-Correlation-ID’: requestId // if no separate correlation ID exists
}
});
return response.data;
}
Message Queue Pattern: When using message queues (RabbitMQ, Kafka, SQS), include request/correlation IDs in message headers or metadata fields to maintain traceability across asynchronous operations.
Logging & Monitoring Integration
Structured Logging with Request Context
Structured logging in JSON format enables powerful log aggregation and analysis:
{
“timestamp”: “2026-02-06T15:23:45.123Z”,
“level”: “error”,
“requestId”: “7f9a4e3c-2b1d-4a5e-8c3f-1e2d3c4b5a6f”,
“correlationId”: “a1b2c3d4-e5f6-7890-abcd-ef1234567890”,
“service”: “user-service”,
“userId”: “12345”,
“message”: “Database query timeout”,
“stack”: “Error: Query timeout\n at Database.query…”,
“metadata”: {
“query”: “SELECT * FROM users WHERE id = ?”,
“duration_ms”: 5000
}
}
Benefits of structured logging with request IDs:
- Query logs by request ID to see complete transaction timeline
- Aggregate error rates by correlation ID to identify systemic issues
- Filter logs by service + request ID for microservice debugging
- Automated alerting based on error patterns within request flows
- Machine learning analysis of request patterns and anomalies
Integrating with Observability Platforms
Modern observability tools automatically extract and index request IDs:
| Platform | Request ID Support | Key Features |
| OpenTelemetry | Native trace/span ID support | Industry standard, vendor-neutral |
| Datadog | Automatic extraction from logs | APM integration, distributed tracing |
| New Relic | Request ID correlation | Full-stack observability, error tracking |
| Grafana/Loki | LogQL label queries | Open-source, powerful visualization |
OpenTelemetry Integration: OpenTelemetry represents the future of request tracking, providing standardized APIs for distributed tracing. Request IDs map to trace IDs and span IDs in the OpenTelemetry model.
Creating Effective Dashboards & Alerts
Leverage request IDs to build powerful monitoring dashboards:
- Request flow visualization: trace paths through microservices
- Error rate trends: group by correlation ID to identify systemic failures
- Performance histograms: analyze latency distributions per service
- Dependency graphs: map service interactions automatically
- Real-time alerts: trigger on specific request ID patterns
Example Query (Grafana/Loki):
{service=”api-gateway”} |= “requestId” | json | requestId=”7f9a4e3c-2b1d-4a5e-8c3f-1e2d3c4b5a6f”
Advanced Patterns & Considerations
High-Performance Systems & Scaling Considerations
Request IDs introduce minimal overhead, but optimization matters at scale:
- UUID generation: ~1-2 microseconds (negligible impact)
- Header overhead: 50-100 bytes per request (0.0001% of typical payloads)
- Logging overhead: Use asynchronous logging to prevent I/O blocking
- Database indexing: Index request ID columns if querying frequently
- Cache warming: Pre-generate UUIDs in high-throughput systems (rarely needed)
Benchmark Data: Adding request ID middleware to a Node.js application processing 10,000 requests/second adds <0.1ms latency on average—well within acceptable performance budgets.
Security & Privacy Considerations
Request IDs can inadvertently expose information or create security risks:
| Risk | Mitigation Strategy |
| Sequential IDs reveal request volume | Use random UUIDs, not auto-incrementing IDs |
| Request IDs in URLs enable enumeration | Never use request IDs as primary identifiers in URLs |
| PII leakage in logs | Sanitize logs; avoid logging sensitive data with request IDs |
| GDPR/CCPA compliance | Implement log retention policies; enable request ID-based deletion |
GDPR Consideration: Request IDs themselves are not personal data, but logs containing request IDs may include PII. Ensure your log retention and deletion processes can purge all data associated with a specific request ID.
Legacy System Integration Strategies
Adding request IDs to existing systems without breaking functionality:
- Proxy-based approach: Add reverse proxy (Nginx/HAProxy) to inject request IDs
- Gradual rollout: Implement in new services first, propagate to legacy systems
- Backward compatibility: Make request ID headers optional; generate if missing
- Database triggers: Auto-populate request ID columns with defaults for legacy rows
- Feature flags: Toggle request ID functionality per environment
Industry-Specific Implementations
Different industries have unique requirements for request tracking:
Financial Services: PCI-DSS compliance requires detailed audit trails. Request IDs must be immutable, tamper-evident, and retained for 1+ years. Integration with SIEM systems (Splunk, QRadar) is standard.
Healthcare: HIPAA audit controls mandate tracking all access to PHI (Protected Health Information). Request IDs link user actions to specific medical records, enabling compliance reporting and breach investigation.
E-commerce: Payment processing errors require request IDs to reconcile transactions with payment gateways (Stripe, PayPal). Include request ID in order confirmation emails for customer service efficiency.
Real-World Troubleshooting Scenarios
Step-by-Step Debugging Workflow
How to leverage request IDs for efficient debugging:
1. Capture the Request ID – User reports error; obtain request ID from error message or response headers
2. Search Centralized Logs – Query: grep “7f9a4e3c-2b1d-4a5e-8c3f-1e2d3c4b5a6f” /var/log/app/*.log
3. Reconstruct Timeline – Sort log entries by timestamp; identify sequence of service calls
4. Identify Failure Point – Look for error-level logs, exceptions, or missing expected log entries
5. Check Upstream/Downstream – Trace correlation ID to see related requests in other services
6. Verify Fix – Reproduce issue; confirm new request ID shows expected behavior
Common Pitfalls & How to Avoid Them
| Pitfall | Solution |
| Request IDs not propagating to downstream services | Ensure all HTTP clients include X-Request-ID header |
| Logging request IDs but not including in errors | Add request ID to all error responses and exceptions |
| Request ID collisions (duplicate IDs) | Use UUID v4; verify generation library is cryptographically random |
| Missing request IDs in asynchronous operations | Pass request ID as function parameter or use async context |
Case Study: Reducing Debug Time by 65%
A mid-sized SaaS company with a microservices architecture implemented comprehensive request tracking:
Before Implementation:
- Average debugging time: 2.5 hours per production incident
- Customer support resolution: 4-6 hours
- Root cause identification rate: 60% (40% remained unresolved)
After Implementation:
- Average debugging time: 45 minutes (65% reduction)
- Customer support resolution: 1.5 hours
- Root cause identification rate: 95%
- Additional benefit: Automated error categorization and routing
Key Success Factors: Consistent implementation across all 12 microservices, integration with Datadog for centralized logging, and user-facing error IDs that created shared context between customers and support teams.
Frequently Asked Questions
Q: How do I generate a unique request ID in my specific language/framework?
A: Most modern languages have UUID libraries built-in or readily available:
JavaScript: require(‘uuid’).v4()
Python: import uuid; uuid.uuid4()
Java: UUID.randomUUID().toString()
C#: Guid.NewGuid().ToString()
Ruby: SecureRandom.uuid
Go: github.com/google/uuid package
PHP: uniqid() or ramsey/uuid library
Q: Should request IDs be exposed to end users?
A: Yes, displaying request IDs in error messages significantly improves support efficiency. Users can reference specific error instances when reporting issues. However, never use request IDs as authorization tokens or expose them in a way that enables system enumeration.
Q: What is the difference between X-Request-ID and X-Correlation-ID?
A: X-Request-ID typically identifies a single HTTP request to one service. X-Correlation-ID spans the entire business transaction across multiple services. In practice, many teams use them interchangeably for simpler architectures.
Q: How do I pass request IDs between microservices?
A: Include the request ID as an HTTP header (X-Request-ID or X-Correlation-ID) in all inter-service HTTP requests. For message queues, add it to message metadata. For event streams, include it in the event payload.
Q: How can request IDs help reduce our mean time to resolution (MTTR)?
A: Request IDs eliminate the manual correlation work that consumes 60-80% of debugging time. Engineers can immediately retrieve the complete transaction timeline, identify the failure point, and trace dependencies—reducing MTTR from hours to minutes.
Q: What logging format works best with request IDs?
A: Structured JSON logging enables powerful querying and analysis. Include request ID as a top-level field in every log entry. This enables filtering, aggregation, and visualization in modern log management tools.
Q: Do request IDs impact application performance?
A: The performance impact is negligible. UUID generation takes 1-2 microseconds. Header overhead is ~100 bytes per request. In benchmarks, request ID middleware adds <0.1ms latency—well within acceptable performance budgets.
Q: How do I convince my team to implement request IDs?
A: Focus on the business impact: 40-70% reduction in debugging time, faster customer support resolution, compliance benefits, and improved system observability. Start with a pilot implementation in one service to demonstrate value before rolling out organization-wide.
Q: What are alternatives to request IDs for distributed tracing?
A: OpenTelemetry provides comprehensive distributed tracing with trace contexts, spans, and baggage. Commercial solutions include Datadog APM, New Relic, Dynatrace, and Jaeger. However, request IDs remain the simplest, lowest-overhead solution for basic debugging needs.
Q: How do request IDs fit into our compliance requirements?
A: Request IDs create immutable audit trails required by PCI-DSS, HIPAA, SOC 2, and other frameworks. They enable forensic investigation of security incidents, demonstrate access controls, and provide evidence of proper data handling. Ensure logs with request IDs meet retention requirements (typically 1-7 years depending on industry).
Conclusion: Implementing Request IDs for Long-Term Success
Request IDs represent a fundamental shift from reactive debugging to proactive observability. By implementing comprehensive request tracking, organizations gain:
- Dramatic reduction in mean time to resolution (40-70% improvement)
- Enhanced customer experience through faster support resolution
- Compliance audit trails for regulatory requirements
- Foundation for advanced distributed tracing and observability
- Data-driven insights into system behavior and user patterns
Start with a simple implementation in your most critical services, validate the benefits with metrics, then expand to your entire stack. The minimal development effort—typically 1-2 days for comprehensive implementation—delivers outsized returns in debugging efficiency, system reliability, and team productivity.

EroThots (primarily at domains like erothots.co, erothots1.com, or erothots.is) is a free adult tube-style site specializing in leaked and aggregated content from OnlyFans, Fansly, Reddit, and similar subscription platforms. It hosts videos, images, gifs, and clips featuring OnlyFans models, pornstars, and amateur creators. In 2026, with OnlyFans still dominant and piracy concerns growing, sites like this remain popular for zero-cost access but come with real trade-offs in quality, legality, and security.
We’ll walk through what the platform offers, how it operates, the types of content, privacy and legal realities, comparisons to official sources, common myths, and practical advice. No judgment, just clear details so you can decide for yourself.
What Is EroThots?
EroThots functions as a large aggregator and hosting site for adult material that originates elsewhere. Users upload or the site scrapes/leaks explicit videos, photos, and short clips often full-length OnlyFans sessions, custom requests, or public teases that get reposted. It emphasizes “leaked” content from popular creators, with categories covering everything from solo performances to hardcore scenes.
The site keeps things simple: search by model name, keyword (e.g., “onlyfans girls,” specific performers), or tags. No mandatory account for basic browsing, though ads and pop-ups are common. It includes sections for videos, image albums, and sometimes gifs or AI-generated porn teasers.
Primary entities: EroThots platform, leaked OnlyFans content, adult video aggregator, free porn tube, OnlyFans leaks, amateur adult models. Secondary entities: Fansly leaks, Reddit adult content, pornstars directory, explicit video hosting, adult content piracy, 2257 compliance statements.
Related keywords and long-tail terms: erothots.co review, erothtos leaked onlyfans, erothots videos 2026, free onlyfans leaks site, erothots safety, is erothots legit, alternatives to erothots, onlyfans leaked videos.
How EroThots Works and What You’ll Find
The platform operates like many free adult tubes: content gets indexed or mirrored quickly after it appears on paid services. Popular searches pull up high-view clips from trending creators, with thumbnails, durations, and basic metadata. Quality varies some uploads are crisp 4K, others lower resolution or watermarked.
Bullet-proof list of typical content types:
- Full or partial OnlyFans videos (solo, boy/girl, fetish)
- Photo sets and albums from subscription pages
- Short clips and gifs for quick viewing
- Leaked custom content or “PPV” (pay-per-view) material
- Occasional live stream recordings or Reddit-sourced posts
Navigation relies on search and category browsing. The site claims 2257 compliance (U.S. record-keeping for adult performers) and has report functions, but enforcement on piracy remains limited.
Safety, Legality, and Practical Concerns in 2026
Browsing EroThots exposes you to heavy advertising, potential malware risks from pop-ups, and trackers. While some trust checkers rate the main domains as “likely safe” for basic access, adult sites in general carry higher chances of redirects or unwanted downloads. Use ad blockers, updated browsers, and avoid clicking suspicious links.
Legally, the core issue is unauthorized distribution. Much of the “leaked” material violates creators’ copyrights and terms of service on OnlyFans and similar platforms. Downloading or sharing can lead to account bans, legal notices, or worse in extreme cases. Creators frequently complain about their paid work appearing free elsewhere, hurting their income.
Comparison Table: EroThots vs Official Subscription Platforms
| Aspect | EroThots (Free Leaks) | OnlyFans / Fansly (Paid) |
|---|---|---|
| Cost | Free | Subscription or PPV fees |
| Content Freshness | Often delayed or partial leaks | Immediate, full access for subscribers |
| Quality & Completeness | Variable, sometimes edited or low-res | Creator-controlled, higher consistency |
| Creator Support | None (harms earnings) | Direct revenue for models |
| Safety & Privacy | Higher ad/malware risk, tracking | Better controls, but still platform data collection |
| Legal/Ethical | Piracy concerns | Authorized, consensual |
Paid platforms win on ethics and reliability; free aggregators win on zero upfront cost but lose on everything else.
Myth vs Fact
Myth: Everything on EroThots is completely free and safe to download. Fact: “Free” often means ad-supported with risks, and downloads can include malware or expose your device. Plus, the content itself may be stolen.
Myth: Leaked OnlyFans sites like EroThots don’t hurt creators. Fact: They directly cut into subscription revenue. Many models report lost income and increased harassment when private content leaks.
Myth: These sites are official partners or mirrors of OnlyFans. Fact: They have no affiliation. OnlyFans actively fights leaks and can ban accounts involved in distribution.
Myth: Using an ad blocker makes EroThots risk-free. Fact: It reduces some dangers but doesn’t eliminate tracking, potential zero-day exploits, or the legal gray area of consuming pirated material.
Statistical Proof and Broader Context
Adult content consumption stays massive, with free tube sites and leak aggregators drawing tens of millions of monthly visitors. EroThots variants reportedly pull significant U.S. traffic. Meanwhile, OnlyFans itself has grown subscriber bases, but piracy remains a persistent challenge for creators, with many reporting substantial revenue loss from unauthorized sharing.
AI-generated adult content has also surged, and some leak sites now mix in or promote it alongside real leaks.
EEAT Reinforcement: Insights from Observing Adult Content Trends
Having followed the adult industry and digital content platforms through shifts from tube sites to subscription models and now AI influences, one lesson repeats: the “free” options almost always come with hidden costs whether lost creator income, security headaches, or lower satisfaction over time. A common mistake? Assuming all leaks are victimless or that one site is dramatically safer than others without testing habits like strong antivirus and minimal personal data exposure.
EroThots fits the classic aggregator mold: convenient for casual browsing but rarely the best long-term choice. Real-world experience shows that supporting creators directly often yields better content, community, and peace of mind. No single site review replaces your own risk assessment check recent user feedback on forums, use VPNs if privacy matters, and remember that platforms evolve (domains shift, content gets removed).
FAQs
What is EroThots exactly?
EroThots is a free adult website that aggregates and hosts leaked videos, photos, and clips primarily from OnlyFans and similar subscription services. It allows browsing explicit content without payment, focusing on amateur models and pornstars.
Is EroThots safe to use?
It carries typical risks of free adult sites: intrusive ads, potential malware from pop-ups, and tracking. Some checkers rate the domains as low-to-medium risk, but using ad blockers, antivirus, and avoiding downloads improves safety. Never enter personal info.
Is using EroThots legal?
Consuming leaked content often involves copyrighted material distributed without permission, raising legal and ethical issues. While prosecution for viewers is rare, it violates platform terms and harms creators. Stick to authorized sources for fewer worries.
Does EroThots have official OnlyFans content?
It specializes in unauthorized leaks and reposts. Official OnlyFans material is only available through paid subscriptions on the actual platform.
What are good alternatives to EroThots?
Paid options like OnlyFans, Fansly, or ManyVids give direct creator support and full access. For free legal content, try mainstream tubes with original uploads or creator teasers. For ethical free viewing, seek public social media posts from models.
Why do people search for “erothtos”?
It’s a common misspelling or shorthand for EroThots when looking for free leaked OnlyFans videos and adult images. High search volume reflects demand for no-cost explicit material.
Conclusion
EroThots revolves around key entities: leaked OnlyFans and amateur adult content, free video and image aggregation, piracy-driven adult tubes, creator impacts, and the ongoing tension between free access and paid platforms.
The adult content landscape in 2026 keeps shifting with stronger creator tools, AI generation, and crackdowns on unauthorized sharing. What doesn’t change is the value of informed choices balancing convenience against real risks and ethics.

Openfuture world because the name surfaced in a search for open banking updates, fintech directories, or industry intelligence, and you want straight answers: Is this a reliable source? What does it actually offer? And does it help cut through the noise in a fast-moving sector?
Your deeper need is practical finding a centralized place to track real progress in open banking and open finance without wading through hype, scattered news, or outdated lists. OpenFuture.World (openfuture.world) positions itself as the largest global source of information on advancements in open banking and beyond. In 2026, with open finance expanding rapidly across regions like Europe, the UK, Brazil, and Asia, having one hub for directories, curated news, and connections feels increasingly valuable.
What Is OpenFuture.World?
OpenFuture.World serves as a dedicated knowledge hub and directory focused on open banking, open finance, and related innovations. It aggregates and curates information to help users discover companies, track news, find events, and connect with peers in the sector.
Unlike a single fintech product or bank API, it functions as an intelligence platform. It highlights “who’s who” and “what’s worth paying attention to” through free resources: a searchable business directory with thousands of entries, daily news curation, articles, presentations, and event listings.
The site emphasizes progress in secure data sharing, third-party provider integration, and innovative financial services enabled by open standards. It covers both regulated entities and emerging players, making it useful for developers, banks, fintech founders, and analysts.
Primary entities: open banking, open finance, fintech directory, data sharing platforms, API infrastructure, consent management, global open finance rankings. Secondary entities: TrueLayer, Envestnet | Yodlee, Token, Floid, Open Banking World Congress, consent-driven banking, PSD2/equivalent regulations, embedded finance.
Related keywords and long-tail terms: openfuture.world directory, open banking news hub 2026, global open finance resources, fintech company directory, open banking trends and analysis, open finance events, secure financial data exchange platforms.
Core Features and How It Works
The platform stands out for its focused, no-frills approach to sector intelligence:
- Business Directory: A searchable database of organizations involved in open banking and finance. Entries include profiles on companies like TrueLayer (financial infrastructure), Envestnet | Yodlee (data aggregation), and Token (banking-enabled commerce). Users browse or search for prospects, partners, or competitive intelligence.
- Curated News and Articles: Daily or regular updates on developments, from regulatory shifts to new product launches and cybersecurity lessons.
- Events and Congress: Listings and details for gatherings like the Open Banking World Congress, designed for efficient networking and insights.
- Rankings and Analysis: Periodic global or thematic rankings that spotlight leading organizations, countries, and individuals driving progress.
Bullet-proof list of practical uses:
- Quickly find and evaluate potential partners or vendors in open banking APIs.
- Stay updated on cross-border developments without following dozens of sources.
- Discover emerging players in data analytics, consent management, or embedded finance.
- Prepare for events or pitches with background on key companies.
- Track broader themes like AI agents in payments or blockchain for consent.
The content tone leans professional and forward-looking, aimed at industry insiders who need actionable intelligence rather than consumer-facing explanations.
Open Banking and Open Finance Context in 2026
Open banking enables secure sharing of financial data with authorized third parties via APIs, with user consent at the center. Open finance extends this to insurance, investments, pensions, and more. In 2026, adoption varies: Brazil leads with high consumer uptake tied to instant payments, while Europe and the UK refine post-PSD2 frameworks, and other regions build foundational infrastructure.
OpenFuture.World tracks this uneven global progress, highlighting successes in personalized services, competition that benefits consumers, and challenges around trust, security, and interoperability.
Comparison Table: OpenFuture.World
| Aspect | OpenFuture.World | General News Sites (e.g., Finextra, TechCrunch) | Broader Directories (e.g., Crunchbase) |
|---|---|---|---|
| Focus | Deep open banking & open finance | Broad fintech and tech | All startups and funding |
| Directory Depth | Specialized profiles and links | Limited or none | Wide but less sector-specific |
| Content Style | Curated, analytical | Fast-breaking news | Company data and metrics |
| Free Access | Strong emphasis on free resources | Often ad-supported or paywalled | Basic free, premium for details |
| Best For | Industry professionals and researchers | General awareness | Investment scouting |
This hub shines when you need targeted, sector-specific depth rather than volume.
Myth vs Fact
Myth: OpenFuture.World is a fintech platform or bank service where you can directly access open banking APIs. Fact: It is an information and discovery hub, not a technical infrastructure provider. Use it to learn about and connect with actual API builders like TrueLayer or Yodlee.
Myth: All open banking directories are basically the same. Fact: Specialization matters. OpenFuture.World emphasizes global progress, rankings, and curated insights tailored to open finance, which sets it apart from generic startup lists.
Myth: Open finance is only relevant in Europe due to PSD2. Fact: Momentum is global. Regions like Brazil show strong consumer adoption, and many markets are implementing or expanding similar frameworks in 2026.
Myth: These hubs just republish press releases with no real value. Fact: Quality curation and targeted directories save significant research time, especially when tracking thousands of organizations across borders.
Statistical Proof and Market Context
Open finance continues expanding. Consumer willingness to share data for better experiences remains high, with reports indicating significant potential shifts in financial services value. Cybersecurity incidents in fintech stayed prominent in 2025, underscoring the need for robust consent and security practices that many directory-listed companies address.
Directories like this help navigate a landscape with thousands of players, from established data aggregators to innovative consent management solutions using blockchain or AI.
EEAT Reinforcement: Insights from Following Fintech Intelligence Platforms
Having tracked open banking developments since the early PSD2 days through multiple regulatory cycles and regional rollouts, one pattern stands clear: professionals who succeed fastest combine technical knowledge with strong ecosystem awareness. A common mistake? Relying solely on broad news feeds and missing nuanced, sector-specific signals on who is actually shipping usable infrastructure.
OpenFuture.World fills that gap with its focused directory and curation. It isn’t perfect no single hub captures every development but its emphasis on free access and global scope makes it a solid starting point. From evaluating similar resources over the years, the most useful ones prioritize transparency (clear about being informational, not advisory) and freshness. Always cross-reference directory entries with official company sites and recent regulatory filings for the fullest picture.
FAQs
What exactly is OpenFuture.World?
OpenFuture.World is a global knowledge hub and directory dedicated to open banking and open finance. It offers a searchable database of companies, curated news, articles, event information, and rankings to help professionals track progress and make connections in the sector.
Is OpenFuture.World an official platform or a news site?
It functions primarily as an independent information hub rather than an official regulatory body or technical API platform. It curates content and maintains a directory to support discovery and learning across the open finance ecosystem.
What can I find in the OpenFuture.World directory?
You’ll discover profiles of fintech companies, data aggregators, API providers, and other organizations involved in open banking. Examples include TrueLayer, Envestnet | Yodlee, and Token, with details to help identify potential partners or understand market players.
How does OpenFuture.World help with open banking trends in 2026?
It surfaces daily news, analysis, and events focused on data sharing, consent management, regulatory updates, and innovations like AI in payments. This keeps users informed on global developments without needing to monitor dozens of separate sources.
Is the content on OpenFuture.World free to access?
Yes, the platform emphasizes free resources including the directory, news, and basic event information. This approach aims to lower barriers for discovering and engaging with the open finance community.
Who should use OpenFuture.World?
Fintech professionals, bank innovation teams, developers building financial applications, analysts, and anyone needing reliable intelligence on open banking and open finance advancements benefit most from its focused resources.
Conclusion
OpenFuture.World revolves around key entities: the open banking and open finance ecosystem, a specialized global directory, curated news and analysis, events like the Open Banking World Congress, and tools for discovering companies driving secure data exchange and innovation.

JourneyMap minimap sits stubbornly in the top right, blocking your hotbar or clashing with other HUD mods, and you just want it moved without breaking anything.
JourneyMap remains one of the most popular and powerful minimap mods for Minecraft Java Edition. It gives you a live radar-style minimap, full-screen mapping, waypoints, cave mapping, and deep customization. In 2026, with Minecraft 1.21+ and newer Fabric/Forge versions, the minimap positioning system is more flexible than ever, including true custom dragging.
Understanding JourneyMap’s Minimap System
JourneyMap displays a small, real-time map in one corner of your screen by default (usually top right). It shows terrain, mobs, players, waypoints, and info like coordinates or biome.
The mod supports two independent minimap presets. Each preset can have its own position, style (square/circular), zoom, displayed elements, and opacity. Switch between them instantly with a single keypress.
Key hotkeys you’ll use often:
- J Open full-screen map (and access settings from there)
- Ctrl + J Toggle minimap visibility
- ** (backslash) Switch between minimap presets
- = / – Zoom minimap in/out
- [ Cycle map types (terrain, cave, etc.)
Position options include: Top Right, Bottom Right, Bottom Left, Top Left, Top Center, Center, and Custom.
Step-by-Step: How to Change Minimap Position
Method 1: Quick Preset Changes (Easiest for Most Players)
- Press J to open the full-screen map.
- Click the Settings icon (gear) at the bottom, or press O.
- Navigate to Minimap (or Minimap Preset 1 / Preset 2).
- Find the Position dropdown.
- Choose from Top Right, Bottom Right, Bottom Left, Top Left, Top Center, or Center.
- Close the menu changes apply immediately.
You can configure Preset 1 and Preset 2 differently, then switch live with the ** key. This lets you have one clean minimap for exploration and another packed with info for building or PvP.
Method 2: True Custom Position (Drag Anywhere)
- Open full-screen map with J → Settings.
- Set Position to Custom.
- Return to the game world.
- Hold the configured move key (or use arrow keys) to drag the minimap freely.
- Fine-tune with the Minimap Key Move Pixel Offset setting (default 0.001) for precise pixel-level control.
Custom mode gives you pixel-perfect placement anywhere on screen perfect when other mods clutter the corners.
Method 3: In-Game Adjustments and Hotkeys
Some players prefer direct controls:
- Open settings via full-screen map for full access.
- Adjust related options like opacity, shape, info slots, and what displays (waypoints, players, mobs, light level, etc.).
Pro tip: After moving, test in different situations underground caves, dense forests, or with shaders active because render layers can shift slightly.
Comparison: Position Options in JourneyMap (2026)
| Position Option | Best For | Flexibility | Easy to Switch? | Notes |
|---|---|---|---|---|
| Top Right (Default) | Standard clean HUD | Low | Yes | Classic placement, rarely overlaps hotbar |
| Bottom Right | When top is crowded | Low | Yes | Good with action bars on left |
| Bottom Left | Players who read left-to-right | Low | Yes | Common with inventory-focused mods |
| Top Left | Minimal interference | Low | Yes | Avoid if you have chat or notifications |
| Top Center / Center | Dramatic or centered builds | Medium | Yes | Can feel intrusive during combat |
| Custom | Perfect personal HUD | Highest | Moderate | Drag freely + pixel offset tuning |
Custom wins for most experienced players once you spend five minutes setting it up.
Myth vs Fact
Myth: You can only put the minimap in the four corners. Fact: JourneyMap supports Top Center, Center, and full Custom drag mode for anywhere on screen.
Myth: Changing position requires editing config files manually. Fact: Everything is done in-game through the settings menu or hotkeys no file editing needed in recent versions.
Myth: The minimap resets position every time you restart Minecraft. Fact: Settings save per world/profile as long as you close the game properly.
Myth: Custom position only works with certain Minecraft versions. Fact: As of 2026 versions (1.21+), Custom drag and presets work reliably on Fabric, Forge, and NeoForge.
Real-World Insights From Years of Modded Play
After running JourneyMap in hundreds of modpacks across different Minecraft versions from 1.16 through 1.21+, the biggest mistake I see is players fighting the default top-right position instead of using the two presets properly. One preset for a minimal radar during exploration, another fully loaded for base building or resource hunting switching with feels like night and day.
Another common issue: conflicts with shader packs or other HUD mods (like AppleSkin or inventory tweaks). Setting Position to Custom and nudging it a few pixels usually solves overlap instantly. In 2025–2026 testing, the in-game settings menu has become even more responsive, with changes applying without needing a relog.
FAQs
How do I move the JourneyMap minimap to a different corner?
Press J to open the full map, click Settings (or press O), go to Minimap settings, and change the Position dropdown to Bottom Right, Top Left, or any preset option. Changes apply live.
Can I drag the JourneyMap minimap anywhere on screen?
Yes. Set Position to Custom in the settings menu, then use arrow keys or the move control to drag it freely. Adjust the pixel offset for finer control.
How do I switch between two different minimap presets?
The default key is ** (backslash). Configure Preset 1 and Preset 2 separately with different positions, sizes, or displayed info, then switch on the fly.
Why can’t I move my JourneyMap minimap?
Make sure you’re not in a conflicting mod setup (like certain VR mods). Try setting Position to Custom, or check that the minimap isn’t disabled. Restarting the game or updating JourneyMap often fixes stubborn cases.
Does changing minimap position affect performance?
Position changes are purely visual and have zero impact on FPS. Adjust opacity or disable heavy features (like high-quality cave mapping) if you need performance gains instead.
Is there a way to completely hide or disable the minimap?
Yes use Ctrl + J to toggle it off quickly, or turn off “Show Minimap” in the settings for a permanent change.
Conclusion
Changing the minimap position in JourneyMap comes down to understanding presets, the Position dropdown, and Custom drag mode. The core entities minimap presets, position options (corners + custom), hotkeys like J and , and in-game settings menu give you full control over how the mod fits your playstyle.
-

 ENTERTAINMENT12 months ago
ENTERTAINMENT12 months agoTesla Trip Planner: Your Ultimate Route and Charging Guide
-

 TECHNOLOGY12 months ago
TECHNOLOGY12 months agoFaceTime Alternatives: How to Video Chat on Android
-

 BLOG12 months ago
BLOG12 months agoCamel Toe Explained: Fashion Faux Pas or Body Positivity?
-

 BUSNIESS12 months ago
BUSNIESS12 months agoCareers with Impact: Jobs at the Australian Services Union
-

 BLOG11 months ago
BLOG11 months agoJalalabad India: A Hidden Gem of Punjab’s Heartland
-

 FASHION11 months ago
FASHION11 months agoWrist Wonders: Handcrafted Bracelet Boutique
-

 ENTERTAINMENT11 months ago
ENTERTAINMENT11 months agoCentennial Park Taylor Swift: Where Lyrics and Nashville Dreams Meet
-

 BUSNIESS11 months ago
BUSNIESS11 months agoChief Experience Officer: Powerful Driver of Success